Enhanced Recruitment Efficiency
Automated scraping, skill prediction, and candidate classification significantly reduced time and manual effort required for hiring.
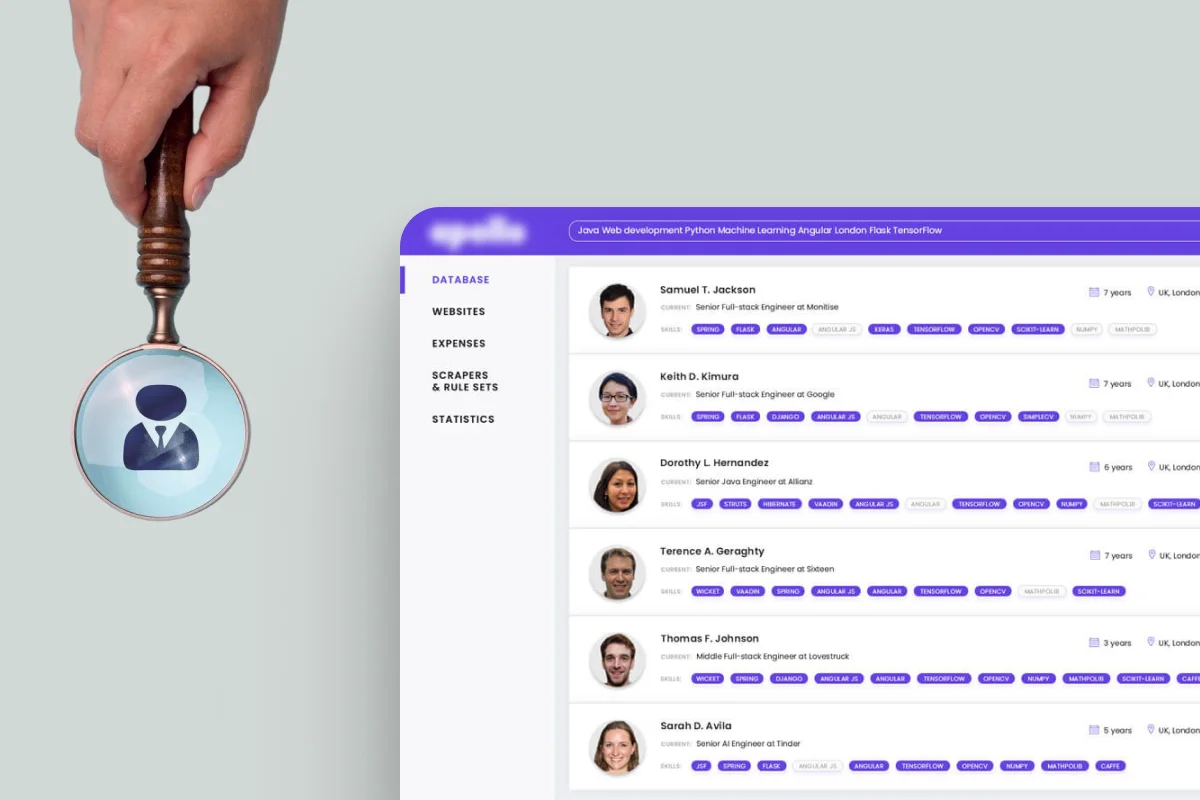
Azati designed and developed a custom recruitment platform for a staffing agency based in New Jersey. The platform uses a network of interconnected microservices to improve the process of resume search, candidate evaluation, and general hiring, ultimately speeding up the recruitment process and enhancing overall efficiency.
increase in relevant candidates identified
average time to classify and tag a candidate
webpages processed per day











The customer needed a custom solution to automatically collect resumes from various websites, create a database, classify candidates, enhance their CVs with missing skills, and enable efficient search across the candidate database. The goal was to improve the hiring process, reducing time and costs for recruitment while ensuring high-quality matches between candidates and job descriptions.
Recruiters were overwhelmed by the manual effort required to search multiple websites and databases for candidate resumes. Candidates often had incomplete or outdated profiles across different platforms, leading to missed opportunities and poor matching between candidates and job roles.
Resume data was scattered across various websites, inconsistent, and sometimes contradictory. This made it difficult for recruiters to build comprehensive candidate profiles and slowed down decision-making.
Recruiters lacked the technical knowledge to understand complex skills, programming languages, and frameworks. Identifying the right candidates for specialized roles was time-consuming and error-prone.
Many websites restricted automated scraping to prevent abuse. Ensuring continuous data collection while respecting these limitations was a significant technical challenge.
We developed dedicated Selenium-based scrapers for each target website, managing proxies and rotating user agents to bypass anti-scraping measures. This ensured reliable extraction of resumes while maintaining a 'normal user' profile, reducing the risk of IP bans or interruptions.
The collected resumes were often incomplete or inconsistent. We transformed this raw data into structured profiles stored in a NoSQL database, enabling efficient searching, merging duplicate information, and enriching candidate data for downstream processing.
A machine learning model analyzed candidate resumes, classified them into skill groups, and predicted missing competencies by correlating known technologies, frameworks, and programming languages. This enhanced incomplete profiles and helped recruiters quickly identify suitable candidates.
All services were deployed in the cloud using Docker containers for scalable web scraping and asynchronous processing. React was used for a responsive, interactive user interface, reducing latency and providing recruiters with real-time access to enriched candidate data.
A robust Search API allowed recruiters to query candidates by skills, predicted competencies, and other attributes. This reduced the time to find suitable candidates, improved the accuracy of matches, and enhanced the overall hiring process efficiency.
Bring your complexity. We'll bring the plan. Tell us about your project and we'll get back within one business day.
Inquire for more infoThis module automatically collects resumes and candidate data from multiple job sites such as LinkedIn, Indeed, Stack Overflow, and Toptal. Each scraper is assigned to a specific website and configured with proxy management and user-agent rotation to bypass anti-scraping measures. The engine extracts unstructured information and forwards it asynchronously for processing, enabling continuous data collection without manual intervention and ensuring that candidate profiles are complete and up-to-date.
After scraping, raw candidate data is often incomplete or inconsistent. This module processes and normalizes the data, converting it into structured formats suitable for search and analytics. Using a NoSQL database, the system can efficiently store diverse data types, merge overlapping information from different sources, and provide recruiters with a comprehensive view of each candidate.
This module leverages machine learning to classify candidates by expertise and predict missing skills based on known technologies, frameworks, and programming languages. Candidates are tagged with relevant groups, keywords, and competencies, improving search accuracy and helping recruiters quickly identify the most suitable candidates.
The Search API provides recruiters with fast, accurate access to the enriched candidate database. It supports complex queries, keyword searches, and filtering by skills, experience, and predicted competencies, reducing the time needed to find suitable candidates.
The platform is fully hosted in the cloud, allowing it to scale efficiently. Docker containers run multiple instances of the web scraping engine to speed up data collection, while asynchronous processing reduces bottlenecks. The React front-end provides a highly interactive user interface, and cloud infrastructure ensures reliability and cost efficiency.
Automated scraping, skill prediction, and candidate classification significantly reduced time and manual effort required for hiring.
Cloud-based architecture and containerized services allowed the platform to scale with growing data and recruiter demand without additional infrastructure costs.
Machine learning-based skill prediction and tagging increased the pool of relevant candidates by 127%, improving job fit and reducing hiring errors.
Average classification and tagging time per candidate decreased to ~4 seconds, allowing recruiters to make faster, more informed hiring decisions.
The system merges partial and duplicate resumes into comprehensive profiles, ensuring recruiters have complete and accurate information.
The staffing agency now experiences faster, more efficient recruitment processes and views Azati as a reliable partner for future technology-driven solutions.

5+ years of backend engineering on a global EdTech platform: 1M+ students, LMS integrations, zero-downtime at billion-record scale.

Custom Redmine plugin development and full-stack upgrade for a DevOps MSP, 30+ plugins adapted, Ruby 3 and Rails 7 migration, zero business disruption.

Mobile app with CNN model for automated steak marbling quality assessment.
Secure locally-hosted LLM alternative for confidential corporate communication.

LLM-powered microservice for automated candidate selection with semantic search.

Custom Jira Service Desk plugin with SLA calculation and task management features.
Last updated