

Artificial Intelligence is one of the most fascinating and controversial technologies in the modern world. Some people are afraid of the consequences. Others can’t wait to see AI-powered machines as it will greatly facilitate many processes, including image detection. And still, others are skeptical about them thinking that AI will never exceed the capability of human intelligence.
This way or another, developers keep working on improving machine learning solutions, and Artificial Intelligence gets more and more advanced. But there is one major issue – despite evolution, AI still seems to struggle when it comes to rendering images. That’s why Image Detection using machine learning or AI Image Recognition and Classification, are the hot topics in the dev’s world.
These three branches might seem similar. Although each of them has one goal – improving AI’s abilities to understand visual content – they are different fields of Machine Learning. So, if you look closer at each branch, you’ll see that there are some critical differences. But, of course, all three branches should merge to ensure that Artificial Intelligence can actually understand visual content.
WHAT IS IMAGE DETECTION?
Image or Object Detection is a computer technology that processes the image and detects objects in it. People often confuse Image Detection with Image Classification. Although the difference is rather clear. If you need to classify image items, you use Classification. But if you just need to locate them, for example, find out the number of objects in the picture, you should use Image Detection.
Let us give you an example. Think of how you’re looking for the keys that are placed somewhere among other things on the table. Even though you’re trying to find one single item, you still scan all the items, and your brain quickly decides whether these are the keys or not. This is how Image Detection works.
The technology is used not only for detecting needed objects. Another popular application area is fake image detection. Using it, you can tell the original picture from the photoshopped or counterfeited one. It is a very powerful and much-needed tool in the modern online world.
HOW MACHINE LEARNING IMPROVES IMAGE DETECTION
This activity of looking for a specific object among others is really simple for a human brain. We do it all the time, we are used to this process. However, computers have obvious challenges with this seemingly easy task. That’s why computer engineers around the world are trying their best to train Artificial Intelligence on how to find the needed objects in pictures. And this is no small task for developers.
To train the AI tool to detect certain objects, you have to show these objects first. In other words, you should ‘feed’ AI with the labeled data – images containing the needed objects, item coordinates, location, and class labels. The most frequently asked question here is “How many images are needed?” The answer is the more, the better.
Also, you should choose images with different locations of the object, so that items change their coordinates and sizes during machine learning. It will help AI understand that even though this object can be located in different places on the image and be both big and small, these changes don’t affect its class.
So, as you can see, it is a time-consuming process that requires lots of resources and efforts.
But let’s look on the bright side. Artificial Intelligence is already making quite a progress here. With GPUs – Graphics Processing Units – deep learning has become much faster and easier. GPU is an electronic circuit that allows to manipulate the memory and accelerate graphics processing.
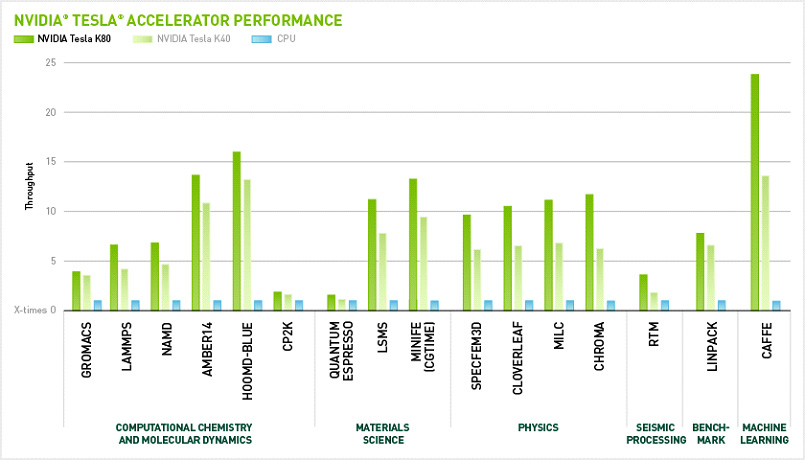
Obviously, that is not manual, but machine learning image detection is the best option. Training a single deep neural network how to solve several problems is more efficient than training several networks to solve one single problem. Thus, smaller parts of the deep neural network will improve its overall performance.
When it comes to applying deep machine learning to image detection, developers use Python along with open-source libraries like OpenCV image detection, Open Detection, Luminoth, ImageAI, and others. These libraries simplify the learning process and offer a ready-to-use environment. You just need to change the code a bit to adjust the model to your requirements.
WHAT IS IMAGE CLASSIFICATION?
It is a process of labeling objects in the image – sorting them by certain classes. For example, ask Google to find pictures of dogs and the network will fetch you hundreds of photos, illustrations and even drawings with dogs. It is a more advanced version of Image Detection – now the neural network has to process different images with different objects, detect them and classify by the type of the item on the picture.
HOW TO TRAIN A NEURAL NETWORK TO CLASSIFY IMAGES?
There are different types of machine learning solutions for image classification and recognition. But the best and the most accurate one is CNN – Convolutional Neural Network. To understand how it works, let’s talk about convolution itself. It’s a process during which two functions integrate and produce a new product. When it comes to pictures, we have to think of an image as a matrix of pixels. Each pixel has its own value but is integrated with other pixels, and it generates a result – an image.
CNN applies filters to detect certain features in the image. The way the convolutional neural network will work fully relies on the type of the applied filter. So, when applying machine learning solutions to image classification, we should provide the network with as many different features as possible. It will then analyze their values upon training.
WHAT ARE THE BEST MACHINE LEARNING METHODS FOR IMAGE CLASSIFICATION TOOLS?
Different tech companies are providing great services that allow building your own model in a matter of minutes. For example, Amazon’s ML-based image classification tool is called SageMaker. It offers built-in algorithms developers can use for their needs. With the help of this tool, they can reduce development costs and create products quickly.
Azure machine learning service is widely used as well. This tool is provided by Microsoft and offers a vast variety of AI algorithms that developers can use and alter. One of the most popular tools is Face API that allows implementing visual identity verification.
WHAT IS IMAGE RECOGNITION?
It is a mix of Image Detection and Classification. Image recognition is the ability of AI to detect the object, classify, and recognize it. The last step is close to the human level of image processing. The best example of picture recognition solutions is the face recognition – say, to unblock your smartphone you have to let it scan your face. So first of all, the system has to detect the face, then classify it as a human face and only then decide if it belongs to the owner of the smartphone. As you can see, it is a rather complicated process.
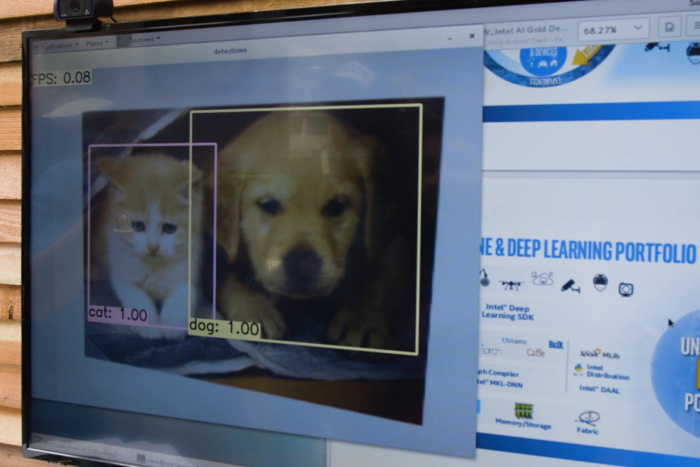
A lot of researchers publish papers describing their successful machine learning projects related to image recognition, but it is still hard to implement them. The training procedure remains the same – feed the neural network with vast numbers of labeled images to train it to differ one object from another.
Although there are some truly amazing results already, image recognition technology is still in its infancy. But even now we can see many ways to implement this technology. For example, developers can use ML-based picture recognition technology for cancer detection to improve medical diagnostics. So, while Google uses it mostly to deliver pictures the users are looking for, scientists can use image recognition tools to make this world a better place.
Of course, the best way to make things work for Artificial Intelligence is to leverage the development processes.
And we are fortunate enough to have a vast number of frameworks and reusable models available in online libraries. Designing models for both deep learning and neural networks from scratch is an extremely resource-demanding activity – and not every computer engineer can go through the process on their own. Therefore, chasing a goal of creating an AI system that will be able to work with visual content properly, devs are eager to share their projects with each other.
So far, developers mostly experiment with various technologies, combining different open-source libraries with services like Azure or SageMaker. But even though this sector is just taking its baby steps, we already have some fairly good things happening. Let’s take Tesla as an example – the car can drive in an autopilot mode. The system scans the environment and makes the decisions based on what it “sees”. The company even claims that the autopilot mode is safer since the system can recognize more threats and is always attentive to what’s happening on the road.
So why is Image recognition software relevant now and how Azati can help you to process images or videos?
In 2022, technologies based on Artificial Intelligence and Deep Learning no longer seem so supernatural. Nevertheless, Image Recognition accuracy only recently improved, making such technologies much more relevant and widespread over the globe. These factors contributed to increasing the usefulness of image recognition, detection and classification:
- The efficiency of Deep Learning has increased, which allows people to create advanced software painlessly. Here’s a closer look at how deep learning has become more powerful over the past 10 years.
- Thanks to the high popularity of smartphones with high-quality and compact built-in cameras and photo-sharing social media platforms, images are proliferating. According to MarketsandMarkets, the global image recognition market size will grow from USD 26.2 billion in 2020 to USD 53.0 billion by 2025, at a Compound Annual Growth Rate (CAGR) of 15.1 % from 2020 to 2025.
Azati is always open to expand new boundaries and keep pace with cutting-edge technologies. Focusing on AI-based solutions we develop qualitative and profitable products. To learn more about how we implemented our experience in computer vision check it out:
- Road Pothole Detection With Machine Learning And Computer Vision
- Automated Data Extraction From Piping And Instrumentation Diagrams
- How To Extract Data From Passports And ID Cards With Azati OCR
SUMMARY
Considering that Image Detection, Recognition, and Classification technologies are only in their early stages, we can expect great things to happen in the near future. Imagine a world where computers can process visual content better than humans. How easy our lives would be when AI image recognition could find our keys for us, and we would not need to spend precious minutes on a distressing search.
