

Many companies have already shifted from physical documentation and leveraged digitized workflows. Yet, there are piles of hard-copy records representing significant value that we need to be convert into a digital form.
Such non-transformed documents are, for example, paper documents that date back to several years or even decades ago. Here are just a few examples:
- Healthcare: medical records of patients
- Architecture: schemes of buildings, construction objects plans
- Publishing: large-scale newspaper digitization projects
- Law firms: law cases
The great news is that a standard document digitization procedure can now deliver you the maximum value you can pull out of the scanned documents! The improvements open up opportunities. For example, having thematically connected documents automatically grouped, extracting relevant contextual data from scanned documents, automatic processing and many others.
But first, let’s start from the very beginning.
DOCUMENT DIGITIZATION ROUTINE. OCR
1) Scanning
This is the first step. So, after you’ve scanned the paper documents, you have their electronic versions existing as a non-text format.
2) Optical character recognition
Optical character recognition (OCR) – is a method of transforming a scanned image into text. Once we scan the paper,the software creates an electronic document, but the computer interprets the text as a number of white and black dots.
We should use OCR in order to make the computer interpret the text from a scanned document as text. By examining the lines and curves of an image, it attempts to determine whether a combination is a particular sign, or a letter:
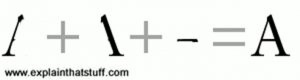
This is how OCR software implements its key function, which is transforming the scanned image into a text file.
It would sound obvious, but due to its relevance we just can’t but mention that having scanned documents in text format rather than as an image is a really instrumental thing. This way, they can be easily retrieved, edited and searched on.
3) Document handling
Managing digital files is another important, but a far more delicate process. One of the most rational solutions is to keep your digital paper documents stored in a document management system (DMS) – the software designed to enable efficient handling over digital assets.
DOCUMENT DIGITIZATION SOFTWARE EMPOWERED BY MACHINE LEARNING
To reveal how OCR can be improved, it’s important to understand its limitations. Influencing factors determining the level of success reads are the following:
1) Handwriting or other marks that cover the text hamper its correct recognition.
Also, lots of elements, such as lines and boxes presented in the file confuse OCR, because it tries to read the lines as part of the text. In that case, the success rate of OCR drops off quickly, and equals only 60%-80% successful read, according to LegalScans.
2) The quality and condition of a paper.
Machine Learning can address the first issue, thus making OCR more advanced.
1. HIGHER ACCURACY OF CHARACTER RECOGNITION
To digitize documents, especially drawings and blueprints, predominantly comprise geometrical figures that make recognition of the text becoming a far more complex task. An ordinary OCR system can’t detect the location of text in such pictures, thus it typically disregards the text.
An ML-based system first identifies the objects (highlighted in red frames). Then, it searches for the text specifically in frames. Such a workflow prevents the system from missing the important information.
2. DOCUMENT STRUCTURE RECOGNITION
Importance
Recognition of document logical structure aims at analysing titles, headings, sections, and thematically coherent parts. This is another great advantage an ML-based OCR system has over a typical one, which is important because:
- It is vital for extracting relevant information
- Allows for automatic indexing and storing, thus alleviating further retrieval of information
- Allows to have the interconnected documents linked (for example, those describing the same object)
Document structure recognition brings in more flexibility in handling your files. If the structure is recognised, you may easily find the document as well as the related ones.
Realization
There are two options to recognise the document structure:
1. Layout Analysis
Entry forms, invoices and other documents have similar structure and are formed according to certain standards, with the equal layout. This often gives many clues about the relation of different structural units like headings, body text, tables, references, figures, etc.
2. Analysing the Content Itself
Keywords can be used to recognize the interrelation and semantics of text.
Why Using Algorithms Is not an Option
Some software service providers offer to embed customized algorithms, so that the software recognises specific parts of a document.
But such an approach lacks versatility. In some projects, there is a need to cope with a vast variety of different document layouts. Additionally, even for the same document type, layouts change in the course of time and the difference between versions becomes more pronounced. Thus, it is inefficient to use algorithms and a more flexible tool is required.
Machine Learning approach
Improvement of algorithms to make them adjust to newly created document layouts is a complex, costly and time-consuming task. Machine learning with its self-learning abilities can continuously improve itself and adjust to the changes quickly. Document structure recognition may be seen as an object detection problem which can be solved by ML.
ML-based solutions are able to estimate the relevance of the document’s elements, so the change of a few elements wouldn’t lead to drastic decrease of accuracy.
3. IDENTIFICATION OF NON-TEXT ELEMENTS
Optical character recognition, as seen from its name, is intended to detect letters, not other elements.
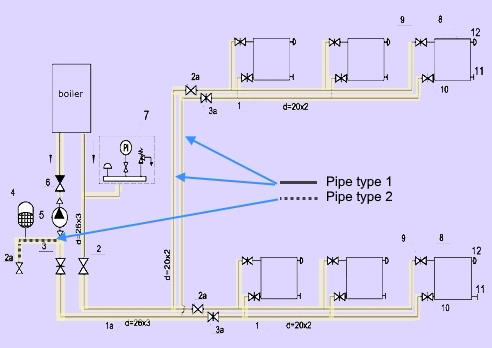
There are cases, when we need recognition of non-text elements, such as lines or geometrical objects.
There are different types of pipes on the blueprint below. So, the ML-based recognition software can detect and differentiate from each type of pipelines.
WHAT CAN YOU DIGITIZE?
Machine learning enabled OCR technology allows you to digitize
- Forms – legal forms, government procedures, etc.
- ID cards – driver’s license, passport, etc.
- Legal documents – tickets, bonds, etc.
- Bank statements – invoices, account statements, cheques, etc.
- P&ID – piping and instrumentation diagrams, etc.
- And much more…
CONCLUSION:
Document digitization is an inevitable fate of papers – sooner or later they all will become digitized. Modern technologies have the power to alleviate this process and empower people to be more flexible over the process of document handling.
